{kind=link}
A great way to add insights to your unstructured PDFs is by ingesting them into an Azure AI Search Index and adding an LLM on top, also known as the RAG pattern as described in: Enhancing Your Data with Azure: Unlocking Insights through Retrieval-Augmented Generation.
This blog posts shows various code snippets, on how to achieve these different steps using Python. The first bit is to setup and populate the Search Index, and the last sections show how to query the search index and enrich the data using GPT.
Please keep in mind that these snippets are a great starting point, but have been kept as small as possible to fit the format of this blog. Comprehensive processing such as chunking, text splitting, enriching, embedding and semantic configuration, semantic reranking have consciously been kept out of the scope of this blog post, but are required for creating an effective search index.
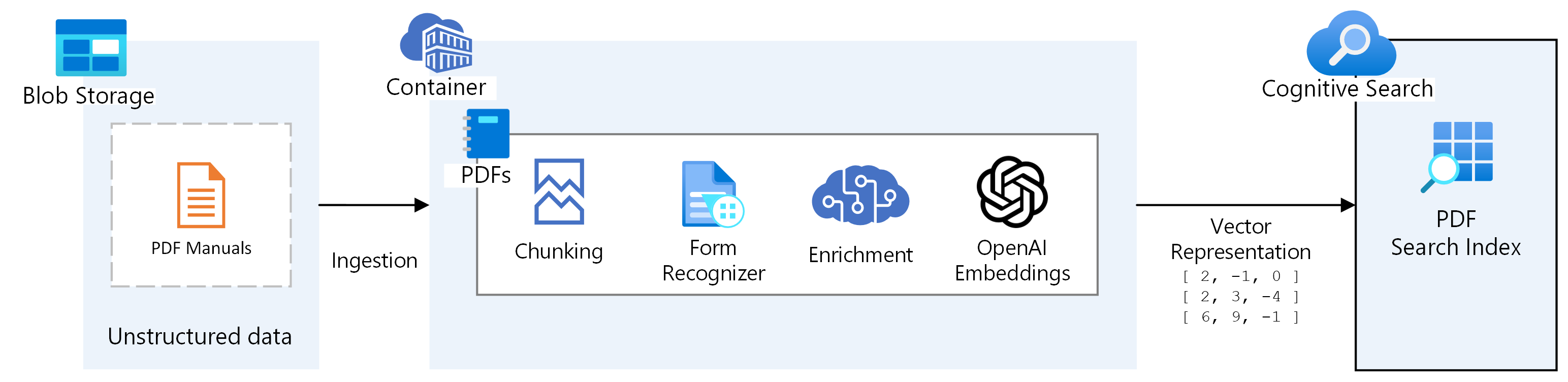
Create Azure AI Search Index
First step is to create an Azure AI Search Index, this can be done through the Azure Portal, the REST API or with the Python SDK:
SEARCH_SERVICE = "your-azure-search-resource"
SEARCH_INDEX = "your-search-index"
SEARCH_KEY = "your-secret-azure-search-key"
SEARCH_CREDS = AzureKeyCredential(SEARCH_KEY)
SEARCH_CLIENT = SearchIndexerClient(endpoint=f"https://{SEARCH_SERVICE}.search.windows.net/", credential=SEARCH_CREDS)
def create_index():
client = SearchIndexClient(endpoint=f"https://{SEARCH_SERVICE}.search.windows.net/", index=SEARCH_INDEX, credential=SEARCH_CREDS)
# Define the index
index_definition = SearchIndex(
name=SEARCH_INDEX,
fields=[
SearchField(name="id", type=SearchFieldDataType.String, key=True),
SearchField(name="content", type=SearchFieldDataType.String, filterable=True, sortable=True),
SearchField(name="sourcefile", type=SearchFieldDataType.String, filterable=True, facetable=True),
SearchField(
name="embedding",
type=SearchFieldDataType.Collection(SearchFieldDataType.Single),
hidden=False,
searchable=True,
filterable=False,
sortable=False,
facetable=False,
vector_search_dimensions=1536,
vector_search_configuration="default",
)
],
semantic_settings=SemanticSettings(
configurations=[
SemanticConfiguration(
name='default',
prioritized_fields=PrioritizedFields(
title_field=None, prioritized_content_fields=[SemanticField(field_name='content')]
)
)
]
),
vector_search=VectorSearch(
algorithm_configurations=[
VectorSearchAlgorithmConfiguration(
name="default",
kind="hnsw",
hnsw_parameters=HnswParameters(metric="cosine")
)
]
)
)
# Create the index
client.create_index(index=index_definition)
This sets up an Azure AI Search Index with these fields:
-
id: ID of the document -
content: plain text content of your document sourcefile: PDF file used, including page number of this documentembedding: vectorized embedding of your plain text content
Since we're using a vector embedding field we configure vector_search, we also setup a default semantic_configuration and define which fields to use for our (non-vector) content (content in our case).
Process PDFs
With the index in place, we need to split PDFs to process, chunk size & overlap size, form recognizer for OCR/Tables, enrichment.
First, we split the PDFs into single page documents:
import io
from PyPDF2 import PdfFileReader, PdfFileWriter
def split_pdf_to_pages(pdf_path):
"""
Splits a PDF file into individual pages and returns a list of byte streams,
each representing a single page.
"""
pages = []
with open(pdf_path, 'rb') as file:
reader = PdfFileReader(file)
for i in range(reader.getNumPages()):
writer = PdfFileWriter()
writer.addPage(reader.getPage(i))
page_stream = io.BytesIO()
writer.write(page_stream)
page_stream.seek(0)
pages.append(page_stream)
return pages
# Example usage
pdf_path = 'path/to/your/pdf/file.pdf'
pages = split_pdf_to_pages(pdf_path)We then use the contents of these single-page documents with Azure Form Recognizer (also known as Azure Document Intelligence), to extract the text from the document:
FORM_RECOGNIZER_SERVICE = "your-fr-resource"
FORM_RECOGNIZER_KEY = "SECRET_FR_KEY"
FORM_RECOGNIZER_CREDS = AzureKeyCredential(FORM_RECOGNIZER_KEY)
def get_document_text_from_content(blob_content):
offset = 0
page_map = []
form_recognizer_client = DocumentAnalysisClient(
endpoint=f"https://{FORM_RECOGNIZER_SERVICE}.cognitiveservices.azure.com/",
credential=FORM_RECOGNIZER_CREDS,
headers={"x-ms-useragent": "azure-search-sample/1.0.0"}
)
poller = form_recognizer_client.begin_analyze_document("prebuilt-layout", document=blob_content)
form_recognizer_results = poller.result()
for page_num, page in enumerate(form_recognizer_results.pages):
# Extract text for each page
page_text = page.content
page_map.append((page_num, offset, page_text))
offset += len(page_text)
return page_map
Split text into indexable sized chunks
With the page contents extracted from the PDF, per page, we can split the text to chunks, an easy way to do this is:
def split_text(page_map, max_section_length):
"""
Splits the text from page_map into sections of a specified maximum length.
:param page_map: List of tuples containing page text.
:param max_section_length: Maximum length of each text section.
:return: Generator yielding text sections.
"""
all_text = "".join(p[2] for p in page_map) # Concatenate all text
start = 0
length = len(all_text)
while start < length:
end = min(start + max_section_length, length)
section_text = all_text[start:end]
yield section_text
start = end
# Example usage
max_section_length = 1000 # For example, 1000 characters per section
sections = split_text(page_map, max_section_length)
for section in sections:
print(section) # Process each section as needed
Note: the snippet above is a very simplistic way of splitting text. In production you'd want to take into account sentence_endings, overlap, word_breaks, tables, cross-page sections, etc.
Create Search Index sections
We can use the page_map from get_document_from_text to call thesplit_text function and setup the sections for our index:
def create_sections(filename, page_map):
for i, (content, pagenum) in enumerate(split_text(page_map, filename)):
section = {
"id": f"{filename}-page-{i}",
"content": content,
"sourcefile": filename
}
section["embedding"] = compute_embedding(content)
yield sectionGenerate embeddings
We can generate embeddings using Azure OpenAI's text-embedding-ada-002 model:
# Configurations
OPENAI_SERVICE = "your-azure-openai-resource"
OPENAI_DEPLOYMENT = "embedding"
OPENAI_KEY = "your-secret-openai-key"
# OpenAI setup
openai.api_type = "azure"
openai.api_key = OPENAI_KEY
openai.api_base = f"https://{OPENAI_SERVICE}.openai.azure.com"
openai.api_version = "2022-12-01"
def compute_embedding(text):
return openai.Embedding.create(engine=OPENAI_DEPLOYMENT, input=text)["data"][0]["embedding"]Ingest Data into Search Index
With the computed sections from create_sections we can batch-upload them (in pairs of 1000 documents) into our Search Index:
def index_sections(filename, sections):
"""
Indexes sections from a file into a search index.
:param filename: The name of the file being indexed.
:param sections: The sections of text to index.
"""
search_client = SearchClient(endpoint=f"https://{SEARCH_SERVICE}.search.windows.net/",
index_name=SEARCH_INDEX,
credential=SEARCH_CREDS)
batch = []
for i, section in enumerate(sections, 1):
batch.append(section)
if i % 1000 == 0:
search_client.upload_documents(documents=batch)
batch = []
if batch:
search_client.upload_documents(documents=batch)
# filename and sections from previous steps
index_sections(filename, sections)The result of this last ingestion step is a fully populated Search Index, ready to be consumed.
Retrieval Augmented Generation
Now we can query our Search Index endpoint, using:
from azure.core.credentials import AzureKeyCredential
from azure.search.documents import SearchClient
def search_index(query, endpoint, index_name, api_key):
"""
Searches the indexed data in Azure Search.
:param query: The search query string.
:param endpoint: Azure Search service endpoint URL.
:param index_name: Name of the Azure Search index.
:param api_key: Azure Search API key.
:return: Search results.
"""
credential = AzureKeyCredential(api_key)
search_client = SearchClient(endpoint=endpoint, index_name=index_name, credential=credential)
results = search_client.search(query)
return [result for result in results]
# Example usage
endpoint = 'https://[service-name].search.windows.net' # Replace with your service endpoint
index_name = 'your-index-name' # Replace with your index name
api_key = 'your-api-key' # Replace with your API key
search_query = 'example search text'
search_results = search_index(search_query, endpoint, index_name, api_key)
for result in search_results:
print(result) # Process each search result as needed
Enrich results with GPT-4
After retrieval, we can enrich the search results with GPT-4:
import openai
def enrich_with_gpt(result, openai_api_key):
"""
Enriches the search result with additional information generated by OpenAI GPT-4.
:param result: The search result item to enrich.
:param openai_api_key: OpenAI API key.
:return: Enriched information.
"""
openai.api_key = openai_api_key
# Construct a prompt based on the result for GPT-4
prompt = f"Based on the following search result: {result}, generate additional insights."
# Call OpenAI GPT-4 to generate additional information
response = openai.Completion.create(engine="gpt4-32k", prompt=prompt, max_tokens=150)
return response.choices[0].text.strip()
# Example usage
openai_api_key = 'your-openai-api-key' # Replace with your OpenAI API key
enriched_results = []
for result in search_results:
enriched_info = enrich_with_gpt(result, openai_api_key)
enriched_results.append((result, enriched_info))
for result, enriched_info in enriched_results:
print("Original Result:", result)
print("Enriched Information:", enriched_info)
print("-----")
Next Steps
As mentioned in the beginning of this blog post, this code snippets can serve as the basis of your RAG ingestion & consumption pipeline. But to come increase the effectiveness of your RAG implementation, there's a lot of improvements that can be made.