{kind=link}
The Azure Search Index can be populated in two different ways. You can either directly push data into the index via the REST API/SDK (left image), or leverage the built-in Azure Search Indexer, which pulls data from a chosen DataSource and adds them to a specified index (right image)
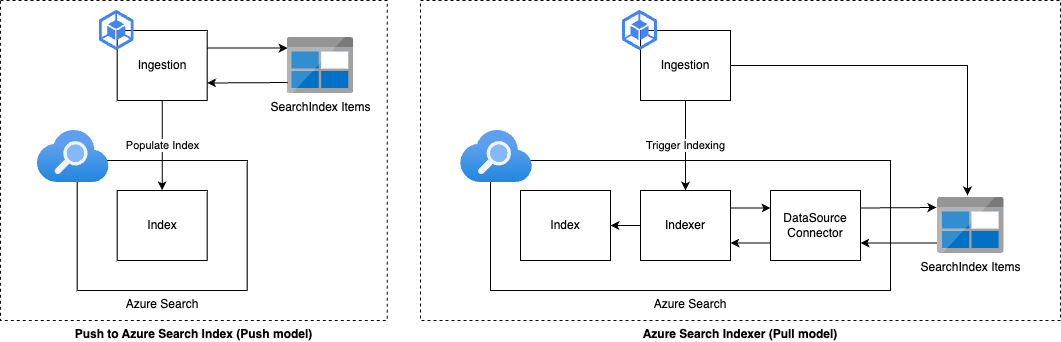
Choosing between the pull and push models depends on the requirements you have. Do you care most about how fast your data gets indexed, or is security your top priority? Maybe you need the flexibility to work with many different data sources. Each model has its own set of pros and cons. To help you decide, we've put together a comparison table below that breaks down the differences between the pull and push models across several important areas, including their ability to enrich data with AI, security features, indexing performance, and more.
| Aspect | Pull Model | Push Model | Notes |
|---|---|---|---|
| Enrichment | ✅ Supports AI enrichment through built-in skillsets. | ❌ Does not support AI enrichment capabilities via skillsets. | Manual enrichment before indexing also possible |
| Security | ✅ Makes use of Azure AI Search's built-in security. | ❌ All security measures must be implemented by the user. | |
| Performance | ❌ Inferior indexing performance compared to push model (currently ~3 times slower)* | ✅ More performant indexing, allows async upload upto 1000 documents per batch. | Indexing performance is key for the overall ingestion duration. |
| Monitoring | ✅ Azure AI Search provides built-in monitoring capabilities. | ❌ User needs to monitor the index status manually. | |
| Flexibility | ❌ Limited to supported data sources; source needs to be compatible with Azure AI Search Indexer. | ✅ More flexible; can push data from any source. | Azure Blob, Data Lake, SQL, Table Storage and CosmosDB are supported at time of writing. |
| Reindexing | ✅ Easily able to reindex with a simple trigger, if data stays in place in DataSource. | ❌ Need to cache documents and manually push each document again | Re-indexing a lot easier with pull model. |
| Tooling | ✅ Indexer functionality is exposed in the Azure portal. | ❌ No tool support for pushing data via the portal. |
The comparison between the pull and push models shows that the pull model excels in areas like AI enrichment, built-in security, monitoring, and ease of reindexing, thanks to its integration with Azure AI Search's capabilities. However, it falls short in indexing performance and flexibility, being slower and limited to certain data sources.
Performance improvements
Feeding data into your search index, whether through push or pull, significantly impacts the overall time taken for ingestion. As seen from the comparison table above, using the push approach can make the process up to three times faster. These results come from the standard configuration, when using a single Azure Search Indexer and a single thread pushing batches of documents to the search index.
Using a dataset with 10,000 documents, we evaluated the performance of ingestions data with the pull and push models under various configurations:
- Upgrade Azure AI Search service tier from S1 to S2
- Add partitions, scaling document counts as well as faster data ingestion by spanning your index over multiple units
- Parallel indexing, using multiple indexers and async pushing documents
We'll have a look at the impact of each individual configuration first, and then combine configurations for further optimizations. To ensure consistency in testing conditions and to mitigate the effects of throughput and latency, all data ingestions were conducted within the same Azure Region, originating from an Azure-hosted machine. The results presented are the average of five test runs.
| Indexer/Pull | Push | |
|---|---|---|
| S1 1 partition | 3:10 | 1:05 |
| S2 1 partition | 2:51 | 0:57 |
| S1 4 partitions | 3:22 | 1:10 |
As shown in the results above, the push method is almost three times faster than using an indexer.Interestingly, the introduction of additional partitions and upgrading to an S2 search instance had a negligible effect on performance in these tests. These results suggest that both the addition of more partitions and upgrading to an S2 search instance primarily enhance capacity and query-performance, rather than directly improving the rate of data ingestion.
To speed things up, we also investigated parallel indexing. For the pull model we can use multiple indexers that write to the same index, and with the push model we can asynchronously push multiple batches simultaneously. Here, we also play with the partition size, to see how that effects the results.
| Indexer/Pull | Push | |
|---|---|---|
| S1 1 parallel | 3:10 | 1:05 |
| S1 10 parallel | 0:20 | 0:59 |
| S1 20 parallel | 0:11 | 0:49 |
| S1 40 parallel | 0:06 | 0:34 |
The performance of the indexer scaled almost linearly with parallelization, showing significant improvements. Specifically, using 10 indexers was approximately 9.5 times faster, 20 indexers around 17.3 times faster, and 40 indexers about 31.2 times faster compared to a single indexer. Although asynchronously pushing batches also enhanced performance, the improvement was roughly 2 times better when using 40 parallel threads for pushing. Increasing parallel threads further had a negative impact and decreased performance for both push and pull.
Considerations
Choosing between the push and pull models for populating the Azure Search Index should be based on project-specific requirements, including indexing speed, security, source flexibility, AI enrichment potential and the need for re-indexing over time. While the pull model integrates closely with Azure AI Search's advanced features, offering built-in enrichment and easy re-indexing, it lags behind the push model in terms of speed and flexibility.
Using standard configurations, the push model outperforms pull and is three times faster. However, you can setup multiple indexers to linearly improve ingestion speed for each indexer added, minding the maximum limit of indexers. This does require a bit of orchestration, where you need to split your indexes over multiple data sources (or folders) and track the progress of multiple indexers.